
* – This article has been archived and is no longer updated by our editorial team –
Enmotus utilizes precision machine learning to help companies optimize the operation of their computer storage solutions. Enmotus’ secret sauce, in addition to precisely identifying the active data set, is that they can move data between the active and capacity tiers in real time as applications needs change. Below is our interview with Adam Zagorski, Head of Marketing at Enmotus:

Q: Adam, could you tell us something more about Enmotus and your product’s unique capabilities?
A: Our product’s unique capabilities allow us to look into the detailed behavior of server storage activity and act upon that behavior to dynamically optimize for both performance and cost. Typically, only a small portion of an organization’s data is active. That data needs to be stored on the highest performing storage for the best performance, and data that is not active needs to be stored on the most cost effective storage. Up till now, it was difficult if not impossible to tell how much of your data was active at any point in time. With our software, it is possible to identify your active data, and properly size your high performing storage media to your application needs.
Q: What kind of products do you offer to your clients?
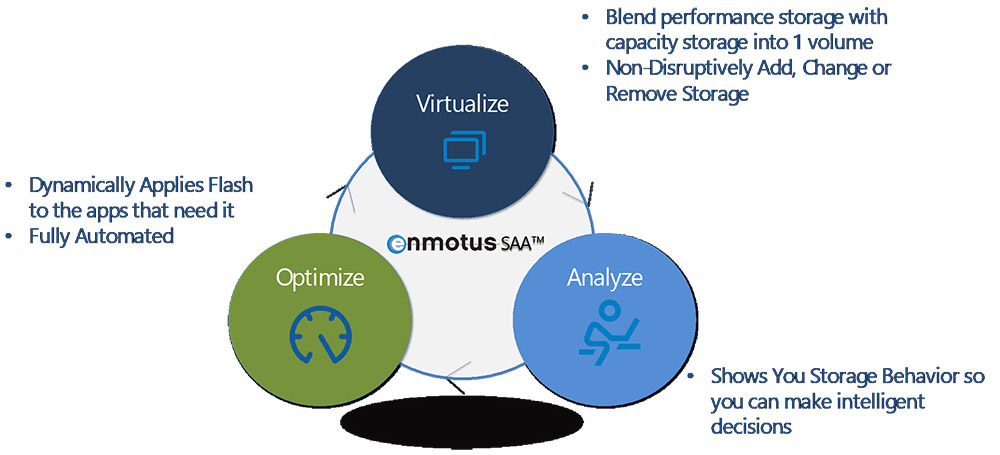
A: Enmotus develops Storage Analytics and Automation software. The product we are currently shipping, VirtualSSD™, blends two different types of storage media such as high performance solid state drives (SSD) with traditional large capacity hard disk drives (HDD), or even high performance NVMe SSDs with more cost effective capacity SSDs, into one single machine intelligent virtual volume. This virtual volume has the performance characteristics of more expensive SSD drives but with the capacity of the less expensive drives. Utilizing spatial usage statistics, the software precisely determines the active data set, then dynamically allocates flash to the applications that require it. The result is an affordable high performance storage solution.
Our primary target market is standalone high performance storage servers, and scale out web scale datacenter server farms.
 Recommended: Quanta Research Institute Releases The World’s First Immersive Lifestyle Camera For Smartphones
Recommended: Quanta Research Institute Releases The World’s First Immersive Lifestyle Camera For Smartphones
Q: You’ve recently announced an industry first demonstration of a fully automated tiered NVDIMM/NVMe volume; could you tell us something more?
A: NVDIMMs are an extremely high performing storage media, but they are also very expensive and limited in their capacity. The challenge with NVDIMMs is how to take advantage of their performance and overcome their capacity limitations in a manner that today’s applications can understand. In conjunction with Micron, who manufactures both NVDIMMS and NVMe flash drives, we used our software to blend the NVDIMM and NVMe drives into one single virtual drive. In other words, the computer operating system saw the two disparate storage media as a single drive. Using our software is an easy way to incorporate the NVDIMM technology into existing environments, resulting in a solution that provides performance, capacity and since it is fully automated, easy to use.
Q: How would you convince someone to start using your Storage Analytics and Automation software?
A: There are three major benefits to our software:
• Saves up to 90% the cost of a typical all-flash array deployment
• Removal of guesswork around flash capacity deployment
• Fully automate the process of balancing workloads to flash provisioning
Since most organizations do not have visibility into how much of their data is active, they rely on the brute force method and overprovision their highest performance storage. We have a tool that you can use to identify your active data set. It is as simple as running our software in what we call Single Media Tier mode. This tool identifies, not only the size of your active data, but also when data is active as well as where in the volume that activity is occurring. Knowing this, it allows you to buy the right amount of performance storage, and then you can use the capabilities of our software to guarantee that your active data is always on your performance storage and automatically moved to cost effective storage if it isn’t.
One of our differentiating features is our ability to analyze and act upon data activity at the block level. In other words, we analyze each individual read and/or write request. Typical analysis and monitoring solutions tend to look at transactions at the file level. A simple analogy would be we look at each individual letter rather than a paragraph or entire document.
 Recommended: Inspirio – Helps You Achieve Your Digital Goals Through Digital Transformation And State Of The Art Digital Solutions
Recommended: Inspirio – Helps You Achieve Your Digital Goals Through Digital Transformation And State Of The Art Digital Solutions
Q: What are your plans for the future?
A: We are just scratching the surface for where our technology is headed, especially as the world begins to embrace IoT and rely ever more on data analytics to make more informed decisions. At the storage layers, as ultra high performance storage media such as NVMe and storage class memory (SCM) becomes prevalent in data centers, the challenge of provisioning and balancing against constantly evolving workloads becomes a huge issue. Enterprise applications need increasing storage performance and humans are no longer able to keep up. Machine intelligence is playing an ever important role in automating the securing the functions in large server pools and the opportunities are current boundless in terms of what intelligent, autonomous storage can do to improve our digital lives.
Imagine a world where the servers in a data center have access to common pools of various classes of storage. The server’s performance requirements are monitored in real time and the proper class and capacity of storage is dynamically and autonomously allocated to the server to meet the needs of the application (without overprovisioning). If the performance storage is no longer needed, it can be returned to the pool. All of this will be done automatically without the need for intervention.
Another challenge faced by datacenters is retiring old storage technology in favor of new technology. Organizations spend months and significant costs migrating data to the new solutions. With Enmotus’ Storage Automation and Analytics technology, once a data volume comes online, you will never have to take it offline. Virtualization of the old solution with the new solution enables for the data to be moved as a background activity while the data is being accessed. Once the transfer is complete, the old solution can be obsoleted or repurposed for another application.
