
Below is our recent interview with Greg Council, VP of Marketing and Product Management at Parascript:

Q: For those who haven’t heard of it, what is the best way to describe Parascript?
A: We are basically an AI company that focuses various machine learning techniques on document-based information (whether the documents are scanned images or born-digital) in order to automate as many manual document processing tasks as possible from document sortation to data entry.
Q: How important is document automation for digital transformation?
A: A digitally transformed organization is typically an organization that is efficient, adaptive and automated. The importance depends entirely on whether your business processes involve document-based information. From what we see, a large percentage of critical processes rely upon information stored within these documents.
Most processes still involve manual document sorting and data entry. Naturally, this slows down processes and introduces errors. It also creates an impediment to scalability where an organization can only work as fast as the number of staff assigned to a given process. Document automation supports organizations to meet the definition of digital transformation by increasing efficiency and speed while removing scalability problems.
![]() Recommended: Prestans Online Academy Connects Teachers From Top American Schools To Students Around The World
Recommended: Prestans Online Academy Connects Teachers From Top American Schools To Students Around The World
Q: What are the key best practices for document automation that lead to successful digital transformation?
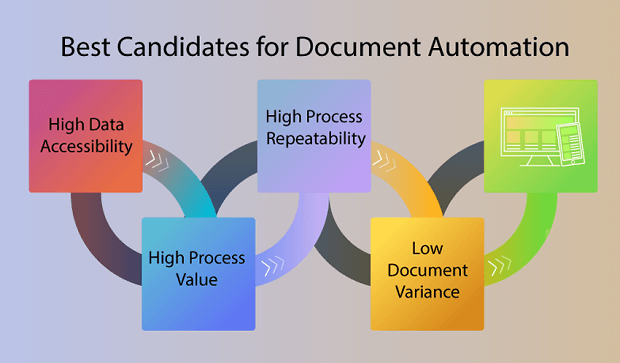
A: Organizations should look at their business processes based upon their attributes to identify the best candidates for document automation. The best processes to automate have high accessibility to data, high process repeatability, high process value and low variance of documents.
The key when it comes to document automation is access to data and the variance of that data. Another best practice is to carefully curate sample sets for system configuration as the amount of automation directly corresponds to the comprehensiveness of the configuration of the system. Failure to include key documents or a document variation can have a dramatic adverse impact on real-world automation.
 Recommended:
Recommended: Q: You have recently launched CheckXpert.AI International France. It can process payments with better than human accuracy and speed. How is this possible?
A: Two words – Deep Learning. But it is more than just using a deep learning neural network (DLNN) on a large sample set. You need to incorporate specific knowledge into the DLNN in order to achieve very good results in a short amount of time or with smaller sample input data. We are continuing to find that these variants of the traditional neural network when combined with some of our own technology, which we have developed over two decades, can produce dramatic results.
Q: FormXtra.AI was named by KMWorld as a 2019 trend-setting product. What specifically sets FormXtra.AI apart from other advanced capture solutions?
A: There are two dimensions to the differentiation for FormXtra.AI. The first is simply the range of use cases that it can support due to the wide range of document types and data types it can automate. These include complex multi-page documents where there are a mix of text and handwritten data. The second dimension is the use of machine learning technologies to simplify the traditionally complex initial and ongoing configuration and system tuning mandatory to achieve high levels of automation.
Using smart learning and sample data, we can reduce to a few hours what would normally take weeks if not months to configure and tune. These two product attributes combined make for powerful competitive differentiation.
Q: What are your plans for the future?
A: I can put future plans down to (1) an expansion of use cases that we wish to support and (2) continued improvement of our Smart Learning capabilities. For uses cases, we are continuing to identify new scenarios and document types where we can improve our capabilities. One area is with highly unstructured documents often involved in complex transactions such as mortgage origination or servicing where we need to identify specific data that could reside anywhere in the document and in any format.
We are also progressing our Smart Learning capabilities to further eliminate the need for manual configuration and tuning for these use cases. A lot of this is with improvements to how the system learns from feedback including the ability to train our recognizers to improve both the amount of data extracted and the accuracy of that data. Our ultimate objective is to provide as close to 100% levels of document automation at accuracy rates of 99% or greater. We may never get there, but organizations will always benefit from our progress towards this goal.
