
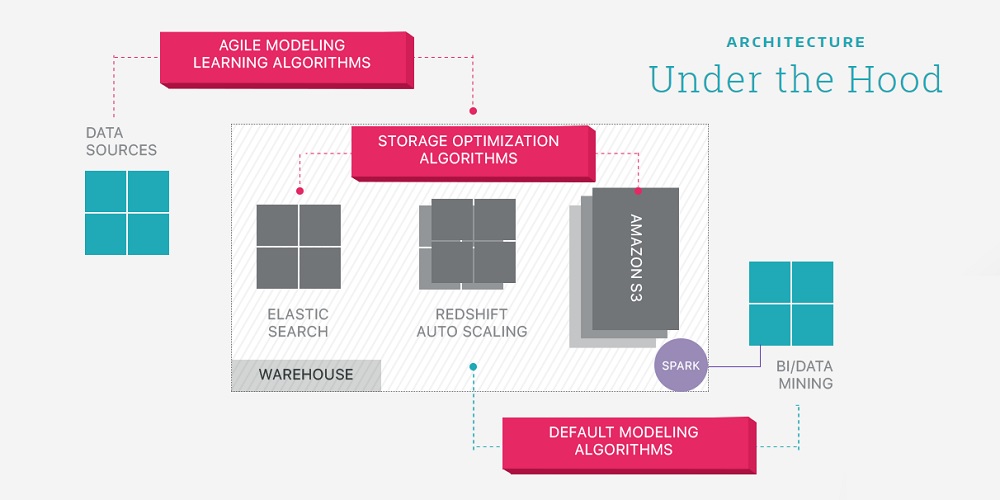
Panoply is the world’s first smart data warehouse. A data warehouse is where a company stores its analytical data, meaning the data that it uses in order to analyze its business. Panoply integrates 3 layers of Machine Learning algorithms to help analysts or data scientists answer business questions. To find out more about their data warehouse solution we sat down with Yaniv Leven, CEO & Co-Founder of Panoply:

Q: You’ve recently announced $6 Million in Series A funding round; could you tell us something more?
A: It was actually $5M, the press did write that it was an extention of the series A but actually it was a different series with a different higher valuation than our series A of $7M from last summer. We were not planning on raising another round till Q1 or Q2 of 2018 but somehow the stars aligned and this opportunity presented itself to work alongside the C5 team and we were more than happy to join forces. We have a couple more very interesting announcements yet to come before year’s end.
 Recommended: Kount’s All-In-One Platform Simplifies Fraud Detection To Help Online And Mobile Businesses Accept More Orders
Recommended: Kount’s All-In-One Platform Simplifies Fraud Detection To Help Online And Mobile Businesses Accept More Orders
Q: Could you provide our readers with a brief introduction to Panoply?
A: Since its concept in the 1970s, data warehouse technologies have been pretty “stupid” technologies, meaning they were pretty much storage with some sort of DB above them. The engineers would then take the Warehouse and manually cast the company’s logic on to it and basically tailor fit the Warehouse to meet the company’s needs to enable the analysts or data scientists to answer business questions. Over the years these technologies got faster and cheaper but to a large extent this is still what’s going on today. Panoply’s warehouse is different, its smart. Panoply’s Warehouse has 3 layers of Machine Learning algorithms incorporated into the architecture so it learns automates and optimizes by itself to tailor fit itself to meet the company’s needs and enable the analysts or data scientists to answer business questions, it does this continuously and agile.
Q: Why is now the time for a technology solution like Panoply?
A: Well a couple of years ago this technology wasn’t really possible. Today with the application of machine learning algorithms being more and more accepted in different genres of technology it is now actually possible to entertain the thought of working alongside algorithms that also “think”. What we are seeing in the market is that smaller and smaller companies are collecting more and more data, so the challenges of the Big data age are now infecting organizations which were pretty much immune to it just a couple of years ago. Data is becoming more fragmented, its growing exponentially, and the extraction of value form it is not necessarily getting that much better. The main reason is that the mission critical path of getting data ready for analysis goes through 2 main stake holders in the company, IT and BI. Two stakeholders with different objectives and different goals, so it is natural that every time something in the process needs to be changed, friction arises that slows down the company from extracting value. Today this inefficiency is estimated at 50%-80% and as the trends continue it is only getting worse. By streamlining the mission critical path to the actual extractors of the value (analysts and Scientist) Panoply eliminates that friction and the inefficiency that comes alongside with it.
 Recommended:
Recommended: Q: What makes you the best solution?
A: Well in terms of Smarts…we’re the only solution. But seriously, Panoply is the only solution that actually eliminates the friction and inefficiencies associated with the mission critical path in the process by streamlining it to one critical stakeholder.
Q: What are your plans for the future?
A: As I mentioned, we have a couple more announcements coming out later this year. We are constantly working on making the platform smarter and simpler for our partners (Business Partners and customers).
Last Updated on October 15, 2017
