
* – This article has been archived and is no longer updated by our editorial team –
Parascript is a 25+ year, innovation-first software company that has introduced highly successful document automation solutions. Below is our recent interview with Greg Council, Vice President of Marketing and Product Management at Parascript:

Q: Could you provide our readers with a brief introduction to Parascript?
A: First, in with the banking industry, we pioneered the ability to handle the classification and recognition of the full stream of transactional documents including checks, deposit slips, etc. combining support for both text and handwritten information. And then, we did it with government post and customs agencies where we automate parsing addresses on all mail including packages with a combination of complex handwritten and printed data. We continue to pioneer novel uses of machine learning technologies to bring high-performing, accurate solutions for any range of document-based data. Today, Parascript software processes over 100 billion documents per year for financial services, government organizations and the healthcare industry.
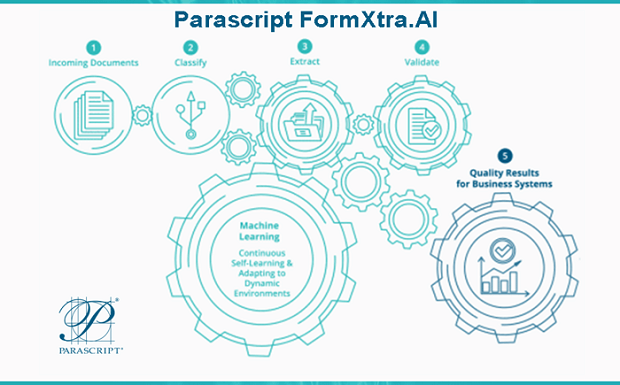
Q: You’ve recently announced the availability of FormXtra.AI; could you tell us something more?
A: FormXtra.AI is the culmination of decades of experience with applied use of neural networks and other machine learning technologies to enable highly-efficient, accurate document classification and data extraction for any type of document. With FormXtra.AI, we introduce the concept of “self-learning” where the system configures itself and continues to adapt to changing demands, all without sacrifice to performance. FormXtra.AI is kind of like “having your cake and eating it too” since it almost completely removes the need for complex, expensive, and time-consuming professional services for configuration, and it even makes decisions on when data is correct or not so that data accuracy is always assured.
 Recommended: Haze Technologies – Aims To Bring The Best And Most Advanced Portable Vaporizers To The Market
Recommended: Haze Technologies – Aims To Bring The Best And Most Advanced Portable Vaporizers To The Market
Q: What exactly is cognitive RPA?
A: Basically, “cognitive RPA” is the ability for RPA systems to incorporate capabilities that mimic the learning and interpretation qualities of human-based thought. Most often it means the ability to use more complex document-based data.
Q: How do information needs drive cognitive RPA?
A: Robotic Process Automation is the evolution of custom script-based automaton of common rote tasks that staff, particularly IT staff, typically perform using a variety of software applications. As the level of use for RPA has expanded “upwards” to more complex, less-defined workflows, these often involve document-based information necessary for carrying-out a process. Take, for instance, a customer onboarding workflow where the customer must submit documentation that: proves who she is, identifies her place of residency, and supports various financial requirements. Certainly RPA can orchestrate the intake of these documents, but it doesn’t have the capabilities required to interpret these more-complex documents. That is where document automation comes in to act as a supplier of data to these RPA-based workflows. Together, we call this “cognitive RPA” because the interpretation mimics the way humans work and allows the RPA system to have greater access to important data.
Q: Is there one document classifier to rule them all powered by artificial intelligence?
A: The answer is “no” – in reality there are many different classification technologies (classifiers) including support vector machines, k-nearest neighbor and neural networks (including deep learning neural networks). There are also the different types of data such as pictures, text-heavy documents and other “in-between” documents such as invoices, emails, etc. Each classifier has its own strengths and weaknesses. The key is to understand when to use each and how to apply them pragmatically that is the core capability of Parascript R&D. Parascript software leverages many different classifiers, using the strengths of each to arrive at the best performance available.
 Recommended: The Afinia L501 Duo Contains The Dye And Pigment Ink Print Heads Along With Both Sets Of Ink Cartridges
Recommended: The Afinia L501 Duo Contains The Dye And Pigment Ink Print Heads Along With Both Sets Of Ink Cartridges
Q: What can we expect from Parascript in the future?
A: The world may be moving towards “digital transformation,” but just because an organization no longer uses paper doesn’t mean that they have transformed themselves. Document-based data is on a significant increase, and our future is in expanding to handle more types of documents and in more ways, building on top of our self-learning platform. This means a single platform will support automation for any document without the traditional cost or complexity typically associated with these solutions.
